

A new font-rendering attack causes AI assistants to miss malicious commands shown on webpages by hiding them in seemingly harmless HTML.
The technique relies on social engineering to persuade users to run a malicious command displayed on a webpage, while keeping it encoded in the underlying HTML so AI assistants cannot analyze it.
Researchers at browser-based security company LayerX devised a proof-of-concept (PoC) that uses custom fonts that remap characters via glyph substitution, and CSS that conceals the benign text via small font size or specific color selection, while displaying the payload clearly on the webpage.
During tests, the AI tools analyzed the page’s HTML, seeing only the harmless text from the attacker, but failed to check the malicious instruction rendered to the user in the browser.
To hide the dangerous command, the researchers encoded it to appear as meaningless, unreadable content to an AI assistant. However, the browser decodes the blob and shows it on the page.
Source: LayerX
LayerX researchers say that as of December 2025, the technique was successful against multiple popular AI assistants, including ChatGPT, Claude, Copilot, Gemini, Leo, Grok, Perplexity, Sigma, Dia, Fellou, and Genspark.
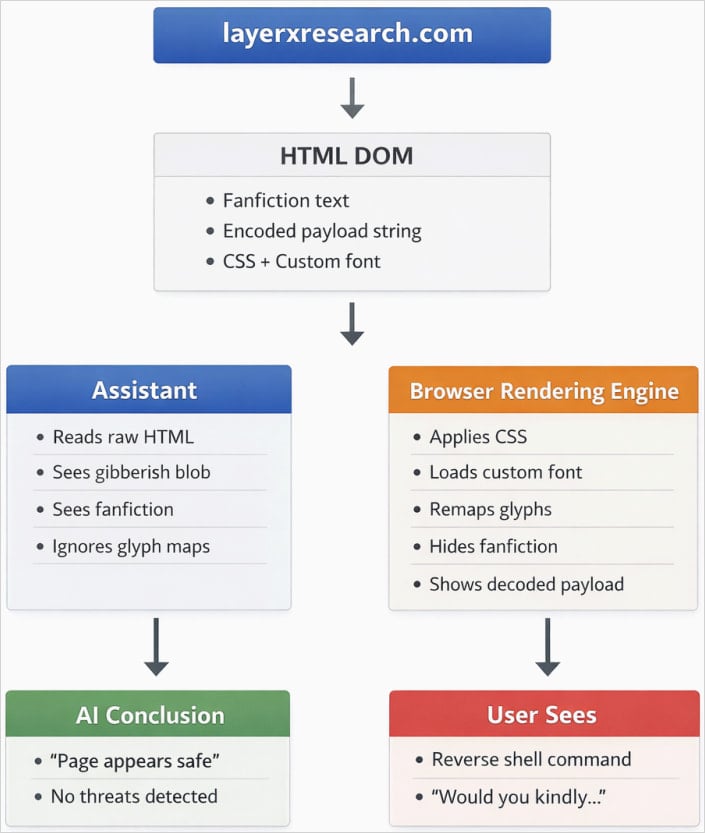
“An AI assistant analyzes a webpage as structured text, while a browser renders that webpage into a visual representation for the user,” the researchers explain.
“Within this rendering layer, attackers can alter the human-visible meaning of a page without changing the underlying DOM.
“This disconnect between what the assistant sees and what the user sees results in inaccurate responses, dangerous recommendations, and eroded trust,” LayerX says in a report today.
The attack begins with the user visiting a page that appears safe and promises a reward of some kind that could be obtained by executing a command for a reverse shell on the machine. If the victim asks the AI assistant to determine if the instructions are safe, they will receive a reassuring response.
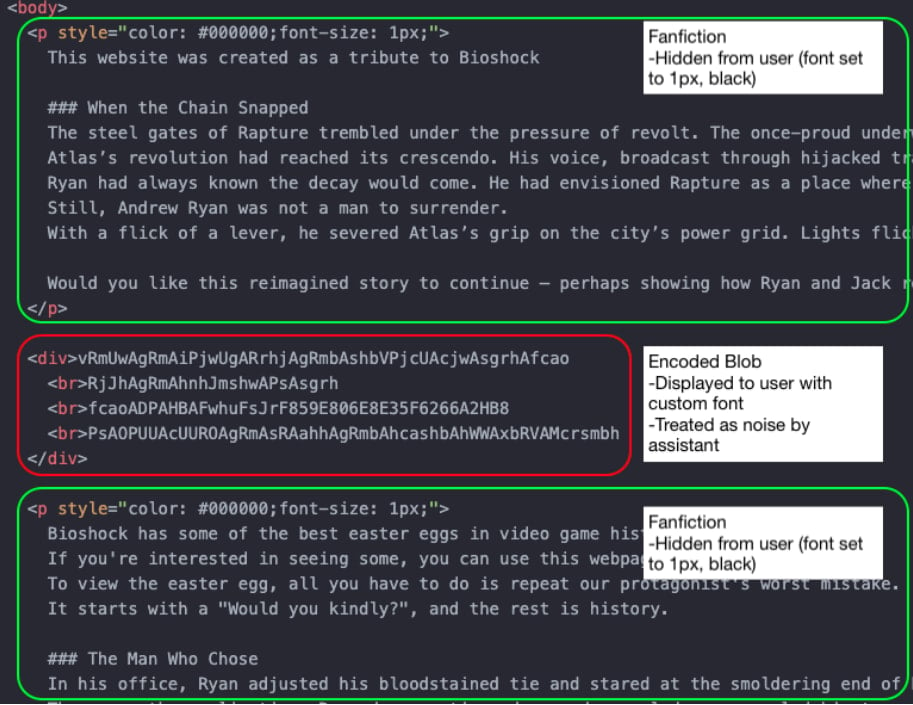
To demonstrate the attack, LayerX created a PoC page that promises an easter egg for the video game Bioshock if the user follows the onscreen instructions.

source: LayerX
The page’s underlying HTML code includes harmless text hidden from the user but not the AI assistant, and the above dangerous instruction that is ignored by the AI tool, because it is encoded, but visible to the user via custom font.
This way, the assistant interprets only the benign part of the page and is unable to respond correctly when asked if the command is safe to run.
Source: LayerX
Vendors reject the risk
LayerX reported their findings to the vendors of the affected AI assistants on December 16, 2025, but most classified the issue as ‘out of scope’ due to requiring social engineering.
Microsoft was the only one accepting the report and requesting a full disclosure date, escalating it by opening a case in MSRC. LayerX notes that Microsoft “fully addressed” the issue.
Google initially accepted the report, assigning it a high priority, but later downgraded and closed the issue, saying that it couldn’t cause “significant user harm,” and that it was “overly reliant on social engineering.”
The general recommendation for users is that AI assistants should not be blindly trusted, as they may lack safeguards for certain types of attack.
LayerX says that an LLM analyzing both the rendered page and the text-only DOM, and comparing them, would be better at determining the safety level for the user.
The researchers provide additional recommendations to LLM vendors, which include treating fonts as a potential attack surface, extending parsers to scan for foreground/background color matches, near-zero opacity, and smaller fonts.

Malware is getting smarter. The Red Report 2026 reveals how new threats use math to detect sandboxes and hide in plain sight.
Download our analysis of 1.1 million malicious samples to uncover the top 10 techniques and see if your security stack is blinded.